Introduction
Data science projects are like any other software project which needs regular maintenance, enhancements, and improvements over some time after the first production deployment. But when it comes to putting ML models in production, companies are already struggling big time, let alone the regular maintenance. As per one report, only 22% of the companies, that ran ML projects were able to deliver them in production successfully. This number is indeed very poor and to make it worse, 43% of the data scientists find it challenging to scale their data science projects as per their company’s needs. This means that data scientists are unable to deliver new improvements consistently and efficiently to meet the growing requirements of the projects.
Exploring Scalability in Data Science Projects
Scalability in a data science project can mean different things in different contexts –
- How efficiently and fast the data scientists in your team can train their ML models on the server to deliver regular changes in production? The training of huge ML models (Deep Neural Network) may take days, hence they need to devise an effective training strategy and tap into the VMs with the right CPU/GPU and memory as per model size and training data volume. Otherwise, the training of ML models will itself become a bottleneck, and the time taken to production will become long, making it challenging to scale.
- How efficiently your ML model can serve the increasing requests in production? The deployment architecture must be robust to enable easy scaling, from handling just a few thousand serving requests up to millions, if necessary. If not much thinking goes into the deployment architecture in the early days, it can become a nightmare later when the load for inference increases.
- How efficiently you can collect data from various sources into your data lake for training your model? People know this process as ETL (Extract, Transform, and Load), and it serves as the prerequisite for bringing data to the ML model. It marks the entry point of any data science project; therefore, you should establish the right set of infrastructure to create a data lake and an ETL process that can scale with the project’s growing demand and complexity. (Scaling the ETL process is a data engineering topic and we are going to limit our discussion around the first two points specific to data science in the remainder of this article.)
Challenges of Scaling Data Science Projects
Generally, the data scientists are not well equipped with the IT and infrastructure aspects of things in the project. This can lead them to make poor choices that can create a bottleneck. E.g. they may start training their ML models on a VM with a low configuration that can unnecessarily elongate the training process. Similarly, they may invariantly start training their models in a VM with high resource than that was really required, thus blocking it from other data scientists who actually needed a high resource VM for training. Sometimes, the data and ML model parameters are so huge, the traditional way of training them in a single VM can also become quite cumbersome.
A survey revealed that 38% of the data scientists accepted that they lack skills for the deployment of ML models. Looking at this state of things, it is too much of an ask to expect them to design deployment architecture that can scale with load. But is the data scientist the only poor soul responsible for everything?
The term data science projects can mislead you to think data scientists are the sole people responsible for running the show. But in reality, delivering an end-to-end data science project requires a collaborative effort among different teams: Data Engineers (for data collection), Data Scientists (for ML model creation and training), and IT and Operations (for deployment). Unfortunately, these teams work in silos resulting in a lack of collaboration, making it difficult to deliver regular changes efficiently in the production to meet project demands.
How to Scale Data Science Projects?
There are several technical, architectural, and process improvements that can be incorporated in a data science project at the very beginning stage to ensure it can be scaled easily in the future as the project matures. We have listed three strategies that can help you create a scalable data science project
1. Automatic Deployment and Resource Management
We need to implement a separation of concerns and acknowledge that Data Scientists should focus on what they do best: creating and training models. We should abstract all the complexity of resource management from them, yet make it readily available. Automatic deployment, resource allocation to the ML models, and auto-scaling as per the needs can achieve this.
The first step of achieving this is by adopting the methodology of containerizing the ML models. Containerization packages all the environmental dependencies and ML models together in a container to ensure consistency in deployment across training, testing, and production environments. Docker is the most popular containerization technology. In a team of multiple data scientists attempting to deploy their containerized models for training, testing, or production serving on a cluster, Kubernetes can streamline the automatic resource allocation for these multiple requests, auto-scale the resources, and orchestrate between multiple containers if needed. So, if there is an increase in load for model serving requests, Kubernetes can manage it for you.
In fact, Kubernetes can easily scale to serve hundreds and thousands of containers, reflecting its market demand, such that all popular cloud providers like AWS, GCP, and Azure offer Kubernetes as a service on their platforms. Despite its flexibility, Kubernetes can still pose challenges for data scientists to work with. Therefore, Google engineers created Kubeflow to add a layer of abstraction over Kubernetes for deploying ML workflows.
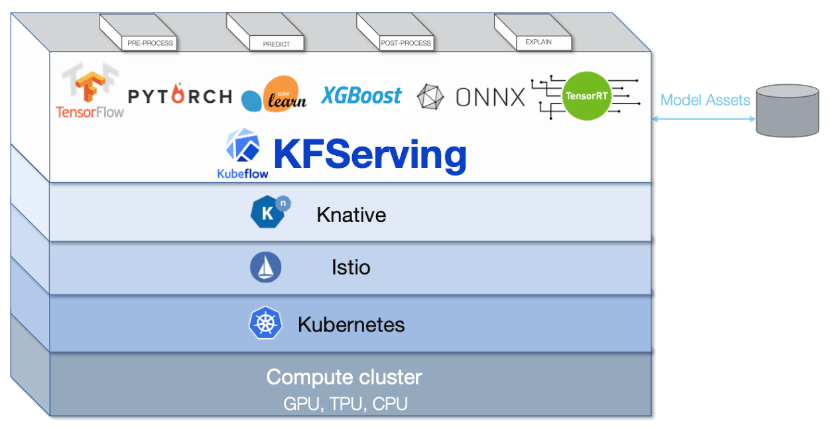
2. Distributed Machine Learning
When working with a huge amount of big data or ML models with thousands and millions of parameters, it can become a computational challenge to train the ML model on a single machine. One possible option here is to scale vertically by adding more RAM size, but it is not a sustainable solution. This is where distributed machine learning can be quite useful to train models with a degree of parallelism and scale up the training process.
There are two strategies for distributed machine learning:
- Model Parallel: This approach is ideal when a model is quite huge, allowing for the distribution of its weights across the machines for computational purposes.
- Data Parallel: In this approach, the multiple distributed nodes have a copy of the ML model and its weights each and is useful to process a huge amount of big data with parallelism on these nodes

For the distributed computation of this nature, traditionally Hadoop and Spark had been the go-to choice and they even have support for machine learning libraries. But now with its growing popularity, Kubernetes can be used to orchestrate a distributed machine learning system to achieve scalability.
3. MLOPs Pipeline
An end-to-end data science project involves many steps, including data collection, ETL, model creation, model training, testing, and production deployment. Since there are multiple teams responsible for different steps and most of the process is manual it makes sense to automate everything end to end in a pipeline. Borrowed from the concept of DevOPs of traditional software projects, is the methodology of MLOPs for creating CI/CD pipelines for data science projects. You can develop your own custom pipeline using Kubeflow or you can leverage pipeline as a service offered by likes of AWS, GCP, Azure.
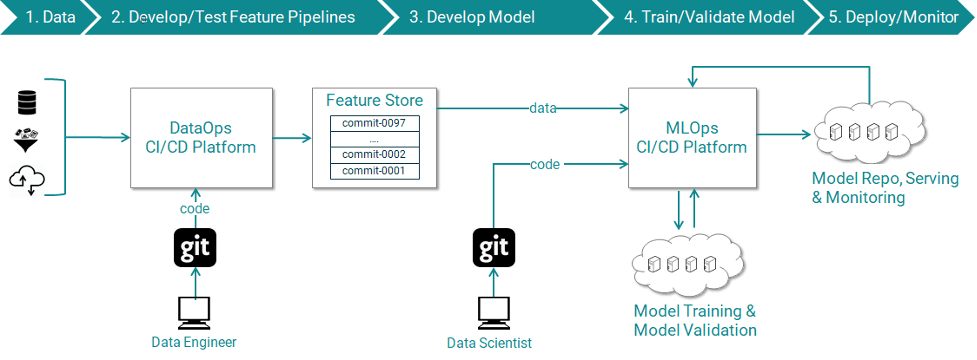
Automating everything from end to end not only eliminates manual touchpoints but also gives room to scale the data science project. Data scientist no longer needs to worry about who from data engineering team is going to help them procure data or who will assist them in deployment from the IT team, pipeline will take care of everything and they can focus on building models and push changes through the CICD pipeline. This helps to reduce time to production and scale up with requirements.
Conclusion
It is quite evident with the current state of data science that scalability is one of the main challenges that companies are facing. It is not that there is a lack of technologies to help you scale the project, it is instead a lack of awareness and skill which is the real underlying issue. Here, we discussed challenges and some strategies for scaling data science projects, and we hope that you will be able to leverage them for your own project as well.